探秘Pingo多存储后端数据联合查询技术
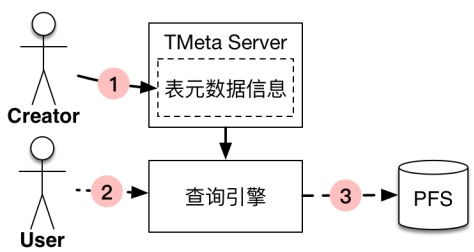
在当今数据驱动决策的时代,企业面临着数据分散存储的挑战,数据可能存在于MySQL、PostgreSQL、MongoDB或云存储等多种系统中。Pingo数据工厂作为一款创新型软件开发解决方案,通过其多存储后端数据联合查询技术,有效解决了这一痛点。
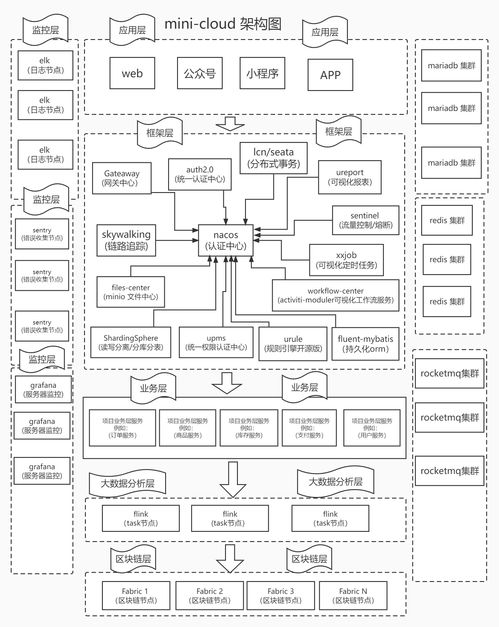
多存储后端架构
Pingo采用模块化设计,支持连接多种数据库和存储系统。它内置了针对不同数据源的适配器,包括关系型数据库、NoSQL数据库、数据湖和文件存储等。这些适配器负责将各类存储系统的查询语言和协议统一转换成Pingo内部的标准格式,从而实现异构数据源的透明访问。
联合查询核心技术
Pingo的联合查询引擎采用分布式查询优化技术,能够智能分析跨数据源的查询请求。当用户提交一个涉及多个存储后端的查询时,Pingo会执行以下关键步骤:
- 查询解析与优化:将SQL或类似查询语句解析为逻辑执行计划,识别涉及的数据源和表。
- 成本模型分析:基于数据分布、网络延迟和系统负载等因素,生成最优的物理执行计划。
- 下推执行:尽可能将查询操作下推到各个数据源本地执行,减少数据传输量。例如,WHERE条件过滤和基本聚合可在源端完成。
- 结果合并:从各数据源收集部分结果,在Pingo引擎中进行最终的数据合并、排序和计算。
技术优势与特性
统一数据视图:Pingo提供统一的SQL接口,用户无需关心数据实际存储位置,即可执行跨库关联查询。
高性能保障:通过并行查询、数据缓存和索引下推等技术,显著提升跨数据源查询性能。
灵活扩展:支持热插拔式存储后端扩展,新数据源可通过开发适配器快速集成。
安全保障:提供统一的数据访问控制和加密机制,确保跨系统数据查询的安全性。
实际应用场景
Pingo的多存储后端联合查询技术已被广泛应用于数据中台建设、企业数据仓库整合、实时数据分析等场景。例如,在电商领域,企业可以同时查询存储在MySQL中的订单数据、MongoDB中的用户行为数据和HDFS中的日志数据,获得完整的业务洞察。
软件开发实践
在Pingo的开发过程中,团队采用了微服务架构和容器化部署,确保系统的高可用性和可扩展性。核心查询引擎使用Go语言开发,充分发挥其高并发性能优势。同时,项目开源社区活跃,持续推动技术创新和生态建设。
随着数据生态的日益复杂,Pingo的多存储后端数据联合查询技术为企业提供了一种高效、灵活的数据集成方案。通过统一的查询接口和智能优化引擎,它正在帮助更多组织打破数据孤岛,释放数据价值。
如若转载,请注明出处:http://www.5p7fl8.com/product/22.html
更新时间:2026-04-15 23:08:19